Introduction
Based on an example open-source benchmark we here provide a few examples on how to improve the performance of a JDBC database application. We also measure the impacts of the improvements to help assess the benefits of each change.
In the article we start out with an open-source benchmark, once published here, but not maintained for years. The authors themselves has acknowledged that the benchmark was irrelevant.
In the course of the work, changes are applied both to improve the transactional correctness of the application as well as improving overall performance. Perhaps you can use any of these techniques in your project as well!
About the Benchmark
The JDBCBench benchmark implements a benchmark inspired by the TPC-B as specified by the Transaction Processing Performance Council. TPC-B has since long been deprecated by the TPC because of its simplicity, but since the actual benchmark results are not a concern of this article it will serve our purposes well.
The TPC-B benchmark implements a bank application. The application keeps track of customers, their bank accounts and their deposits and withdrawals. Besides the account balance, the application must also keep track of the teller balance and the branch office balance. If a customer visits a local bank office and withdraws 1000 Euros from teller no. 1 in that office, the application must deduct 1000 Euros from the customer’s account balance, teller no. 1’s balance and the branch office balance.
The database consists of four tables, ACCOUNT, TELLER, BRANCH, and HISTORY. The history table logs all deposits and withdrawals.
Each withdrawal and deposit forms one transaction which involves updating the account balance, teller balance, branch balance, writing a log entry to the HISTORY table and querying to determine the resulting customer account balance. In the benchmark, this transaction is performed over and over again.
Original Implementation
We started out modifying original JDBCBench to better suit the demonstration purposes of this article where we basically removed the pseudo-parallel architecture (the benchmark was using multiple threads but only a single database connection) and started out with an application which is using
java.sql.Statement
objects to execute statements and queries.
For example, to update the ACCOUNTS table, the following code is used:
Statement Stmt = Conn.createStatement();
String Query = "UPDATE accounts ";
Query+= "SET Abalance = Abalance + " + delta + " ";
Query+= "WHERE Aid = " + aid;
Stmt.executeUpdate(Query); Stmt.clearWarnings();
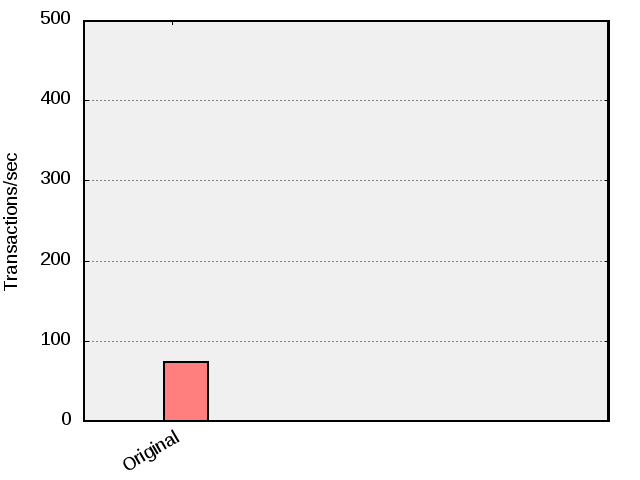
When executing this version, we were able to complete 74 TPC-B transactions per second in the test machine.
It may be worth mentioning that the tests here were run on a regular office laptop with disk write caching enabled. In this setup it was confirmed that the maximum I/O throughput was about 600 writes/second which in conjunction with that the delay commit feature was disabled gives a theoretical maximum transaction throughput of about 600 database transactions/seconds.
Transactions – the Magic Word
Mimer SQL supports transactions and transactions give you an edge. First and foremost, transactions enable you to group operations that logically belong to each other and execute them atomically. Transactions also let you change your mind and revoke changes, you can rollback the transaction. And, whenever you have successfully committed a transaction, you can be (practically) certain that that piece of information will never be lost.
To make sure transactions aren’t lost once committed, each transaction is saved to disk before control is returned to the application. In this particular example, we have four updates and a select that logically belong to each other in each step.
JDBCBench runs in auto-commit mode, which means that all statements are independently committed and saved to disk, before the next statement is executed. This can be compared with the manual-commit approach, where the four updates and the select form one transaction whose database changes are secured on disk in one single disk write. Since disk operations are by far the most time-consuming task in a database system, we can, in theory, experience a four-fold improvement in performance by committing each transaction manually.
1st Improvement
So, we changed the benchmark to use transactions. We switched auto-commit off and issued a manual-commit after each TPC-B transaction.
The changes involved adding only two lines, switching to manual commit mode:
Conn.setAutoCommit(false);
And committing at the end of every TPC-B transaction:
Conn.commit();
After these modifications, besides from the application now being transactionally correct, the benchmark completes 179 transactions per second which is some 150% faster.
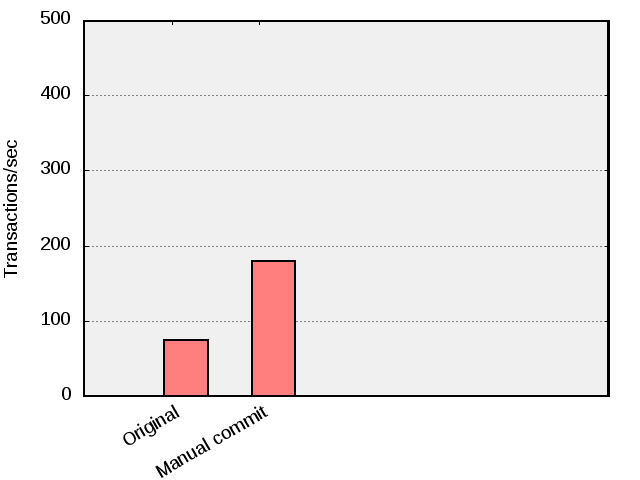
Comparing original version with a test run in manual commit mode.
An added bonus is that the application will never leave the data in an inconsistent state no matter what happens to the environment (power failure, disk crash, or even application failure).
Closing Resources
A common mistake Java programmers make is to rely entirely on garbage collection to close statements and result sets. Even though garbage collection will eventually work, performance and scalability are improved if your application explicitly closes objects when it’s done with them.
The problem is that each client object possibly consumes resources on the server. A large scrollable result set could use megabytes of memory on the server. It is beneficial for the server to know as soon as possible that it can release such resources. If client objects aren’t closed, they will be closed automatically at the next garbage collect, but that might not happen for a long time. It all depends on the memory allocation strategy of the Java Virtual Machine (JVM). A JVM might not collect the garbage until it runs out of memory on the client, and that could take forever.
2nd Improvement
So, the next improvement we decided to make was to close all client objects when done with them. One example being the result set created in the benchmark. The code for that is now:
int aBalance = 0;
ResultSet RS = Stmt.executeQuery(Query);
try {
Stmt.clearWarnings();
while (RS.next()) {
aBalance = RS.getInt(1);
}
} finally {
RS.close();
}
As it happens, this particular benchmark does not consume any server resources worth mentioning so in this case there is little improvement.
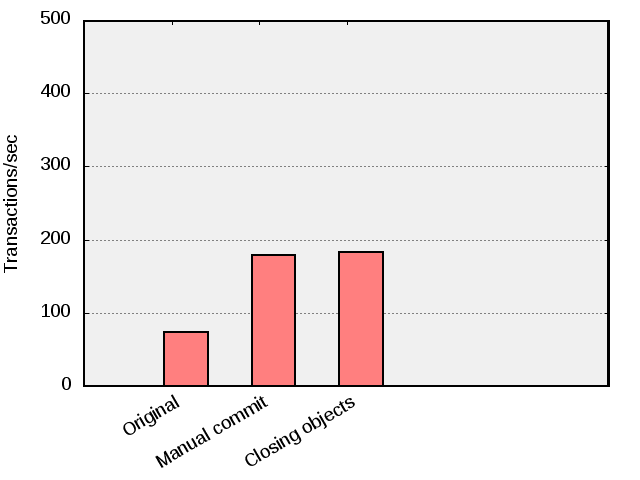
In this particular case, no noticeable improvement is seen when all database objects are closed properly.
One can however not take this for granted. It depends on the type of query or statement, or the data types being used. If problematic, expect to see in the neighborhood of a 10% penalty if one relies on the garbage collection to release server resources.
Cut Back on Statement Compilations
In a JDBC database application, each SQL statement sent to the server is compiled. Compilations are costly, particularly if the SQL statements are complex and there are many possible optimization choices. Sometimes, compiling and optimizing the query is more time-consuming than running the query itself. It is therefore important, and vital to server throughput, to minimize the number of statement compilations.
JDBCBench makes extensive use of java.sql.Statement objects. The Statement object class is the easiest and simplest way of executing SQL statements, but also the most expensive. For each statement, the application builds an SQL statement string which is executed once and then forgotten. The string concatenation process is in itself expensive.
The equivalent approach for a Java program is to have code to generate a Java source dynamically, compile it, execute and then forget it. For example, if we want to implement a function for calculating the formula f(x,y)=x*y+1, we could generate the class below, compile, and execute it if we wanted to calculate f(2,3).
class Formula {
static int f() {
return 2*3+1;
}
}
No one would do that. Instead we implement the class below, which uses input parameters.
class Formula {
static int f(int x,int y) {
return x*y+1;
}
}
In the second example, we only need to compile the class once. We can execute it many times since the parameters are supplied at runtime.
Now that we realize the benefits of avoiding compilations, we want to do the same thing in SQL. Suppose we want to run a simple query in the personnel table below. (This table and these examples are not part of the benchmark.)
create table STAFF (
ID integer primary key,
PRENAME char(20),
SURNAME char(20)
)
We have an id-number and we want to know the name of the person on staff that it belongs to. A novice database programmer might implement it like the following.
1 class MyClass {
2 String queryName(Connection con,id int) {
3 Statement stmt = con.createStatement();
4 String sql = "select PRENAME,SURNAME from STAFF "+
5 "where ID="+id;
6 ResultSet rs = stmt.executeQuery(sql);
7 rs.next();
8 String name = rs.getString(1)+" "+rs.getString(2);
9 rs.close();
10 stmt.close();
11 return name;
12 }
13 }
Each time the queryName method is called, we do everything over again. We allocate a new SQLStatement object each time (line 3), we build an SQL-string each time (4-5), and we compile and execute the statement each time (6). We want a better way! See below.
1 class MyClass {
2 PreparedStatement pstmt;
3
4 MyClass(Connection con) {
5 pstmt = con.prepareStatement(
6 “select PRENAME,SURNAME from STAFF where ID=?”);
7 }
8
9 String queryName(id int) {
10 pstmt.setInt(1,id);
11 ResultSet rs = pstmt.executeQuery();
12 rs.next();
13 String name = rs.getString(1)+” “+rs.getString(2);
14 rs.close();
15 return name;
16 }
17
18 void close() {
19 pstmt.close();
20 }
21 }
The program above compiles the statement once (lines 5-6) through the constructor, but the statement can be compiled using any other method. The method MyClass.queryName is called with the parameters once for each execution. The parameters are supplied at line 10. As we learned earlier, we shouldn’t rely on garbage collection, so we close our database objects explicitly.
Reuse those Statements!
Nowadays, Web applications establish a lot of short-lived connections to the database, often through a connection pool. The nature of a Web application is to connect to the database, query it, generate a Web page and then disconnect. The Web application cannot keep prepared statements open between requests.
This poses a big problem as the Web application has to allocate new PreparedStatement objects at every request. The application must construct the SQL string and compile the statement at every request, and we haven’t achieved much. The application’s performance suffers because of too many compilations.
To improve performance, Mimer SQL will, whenever possible, reuse compiled statements and query plans. This happens when the Mimer SQL compiler preprocessor determines that a particular statement has been compiled before. Statements can be reused even when they are issued on different connections, which is good for Web applications which often issue the same query over and over again from different connections.
To maximize the benefits this Mimer SQL feature, your application should issue identical SQL statements. Remember, each time a statement that has never been compiled before is created, performance suffers. Every statement with hard-coded parameters is regarded as a different statement.
Imagine a Java-program that makes use of Statement objects to insert employees in the STAFF-table listed above. The sample Java-program uses Statement objects and concatenates new SQL strings over and over again. In the end, the given program will compile the following statements. (We are using the names of Swedish prime ministers here.)
insert into STAFF values (4709,'Göran','Persson') insert into STAFF values (4710,'Ingvar','Carlsson') insert into STAFF values (4711,'Carl','Bildt') insert into STAFF values (4712,'Ingvar','Carlsson') insert into STAFF values (4713,'Olof','Palme') insert into STAFF values (4714,'Torbjörn','Fälldin')
The inserts results in a number of statement compilations which are all considered different. We can’t reuse the compilations.
On the other hand, if we examine the improved program, we can see that this example uses
java.sql.PreparedStatement
objects and parameter markers. The statement is prepared once before execution, and the parameters are supplied at runtime. Some systems may only compile this statement once, when the application is executed for the first time. And when other users run the same application later, the compilation will be reused.
3rd Improvement
The improvement at this stage is to replace the
java.sql.Statement
objects with
java.sql.PreparedStatement
objects. PreparedStatement objects are provided with an SQL statement at its creation which is never changed. The SQL statements use parameter markers in order to be able to reuse compiled statements. The SQL statement is compiled once, at object instantiation, and executed many times.
Instead of the code to update the ACCOUNTS table:
Statement Stmt = Conn.createStatement();
String Query = "UPDATE accounts ";
Query+= "SET Abalance = Abalance + " + delta + " ";
Query+= "WHERE Aid = " + aid;
Stmt.executeUpdate(Query); Stmt.clearWarnings();
we now do the following once:
String Query; Query = "UPDATE accounts "; Query+= "SET Abalance = Abalance + ? "; Query+= "WHERE Aid = ?"; pstmt1 = Conn.prepareStatement(Query);
and the below many times:
pstmt1.setInt(1,delta); pstmt1.setInt(2,aid); pstmt1.executeUpdate();
When done with these changes one can see that the application throughput has increased to 303 transactions/second.
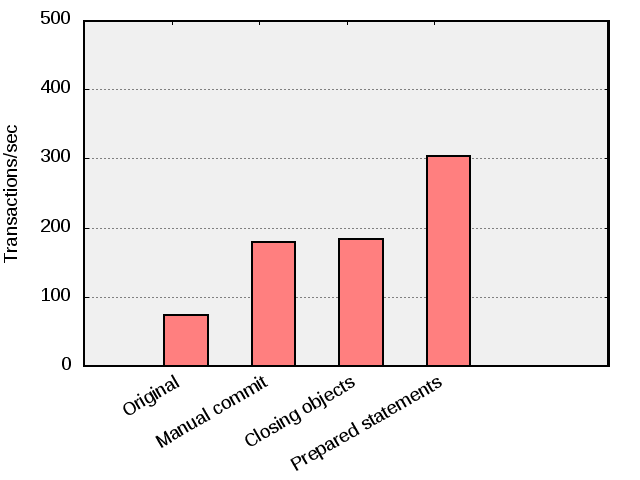
Modifying the benchmark to use prepared statements increases performance with about 50%.
If you want to go further – Procedures
We can refine JDBCBench even further. All the previous programs made separate server calls for each statement. This means each statement talks to the server using a communication call of its own. Each communication includes some overhead both at the client and the server as well as transfer time for the message to get through. If the network is slow or if there is a lot of network traffic communication times can be very, very long.
One solution to this problem is to embed several statements in a procedure. This application is very well suited for this since each transaction involves updating several tables from the same application data.
The 5th and Final Improvement
Finally, we changed the benchmark to use procedures. We removed the separate update, select and insert statements and created a procedure which is called once for each TPC-B step.
This version of the benchmark managed to complete 368 transactions per second which is a 20% improvement over the previous version.
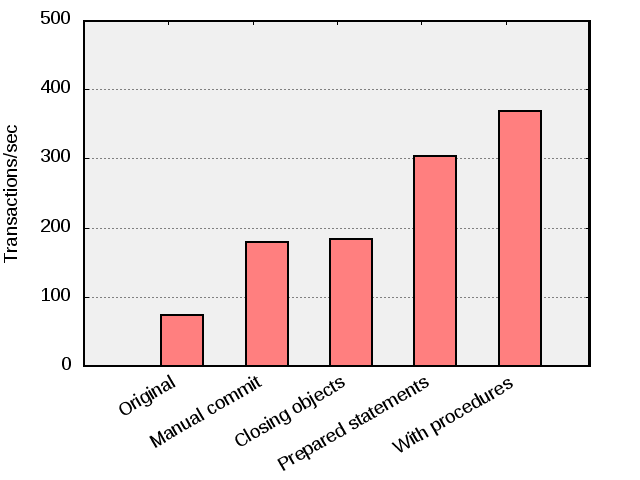
Implementing critical parts of the application in a stored procedure provides an additional 20%.
I/O bound or CPU bound?
The measurements made here indicate that the performance of the application, isthat the performance of the application, is “CPU bound”. This means that it is the available CPU performance which limits overall performance. If the system would have been “I/O bound”, meaning that it is the disk I/O which is limiting performance, results would be different.
To illustrate this, all above tests were run again, now with disk caching off.
Besides the obvious that overall transaction throughput is significantly lower than with caching enabled, one can clearly see that the performance levels off at about 40 transactions/second. The improvements “Closing objects”, “Prepared statements” and “With procedures” seems to have given next to nothing. This is because these three improvements primarily reduce the server CPU load, but if there is apparently enough CPU to serve the application under these conditions.
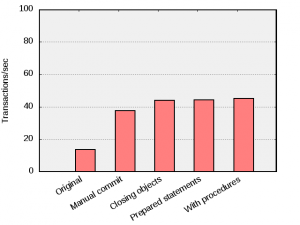
All tests run again with disk caching turned off.
Conclusion
If you experience performance problems with your JDBC database application, consider investigating and improving the following things:
- Make sure you explicitly close database objects as soon as they’re not needed.
- Minimize server compilations by using PreparedStatement objects and parameter markers.
- Realize that transactions are good for server performance and put operations that belong to each other logically in the same transaction.
- Recognize situations that involve multiple statements that can be executed without client processing and embed these statements in procedures.
